Bitpie下载|谁能代替英伟达? -
原文来源:远川科技评论
作者:叶子凌/何律衡

图片来源:由无界AI生成
今年夏天,英伟达创始人黄仁勋专门腾出时间,拜访了一家名叫战略与国际研究中心(CSIS)的智库。在美国,智库的意见能在很大程度上左右华盛顿的政策走向,深处科技战前线的黄仁勋自然深知这一点。
黄仁勋上来就是一顿彩虹屁,并明确表达了捐赠的意向。随后他话锋一转,表示有一位小同志严重拖累了智库队伍的整体水平,建议清除出去。
这位小同志不是别人,正是CSIS高级研究中心主任Gregory C. Allen,也是美国芯片出口管制政策的坚定鼓吹者。
面对美国的打压,英伟达似乎比中国公司还着急。过去数月,黄仁勋一直在竭尽全力阻止制裁落地。

Gregory C. Allen,为数不多能拿捏黄总的男人
除去给智库施压,黄仁勋还当面警告了华盛顿决策层,认为制裁会造成严重代价。与此同时,他还不忘敦促美国半导体行业协会发表谴责声明,强调进一步限制将损害行业的竞争力[2]。
今年7月,黄仁勋还拉上高通和英特尔去了趟华盛顿,目的也是说服美国政府放松对华限制。
然而,美国依然在10月17日更新了芯片出口管制,中国特供版芯片H800和A800也被列入禁售范围。更令人惊讶的是,用于游戏的消费级显卡RTX 4090也进了名单。
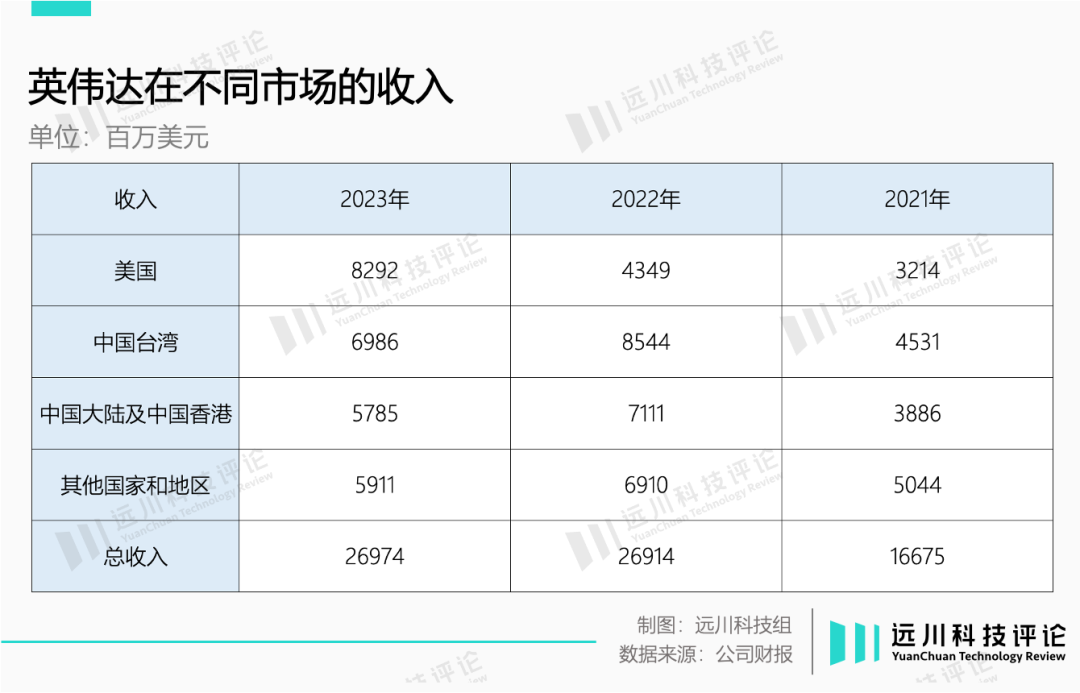
这对英伟达来说无疑是致命一击,长期以来,中国大陆市场一直占据其20%以上的收入。10月17日出口管制发布当天,英伟达股价下跌近5%,AMD和英特尔也跟风跌了1%。
那么,英伟达是否真的无法替代?中国市场之于英伟达又意味着什么?
最好的选择
简单来说,美国政府在新的出口管制政策中添加了多个新指标,不仅把特供产品H800和A800牢牢卡死,还顺便误伤了消费级显卡RTX4090,搞得国内黄牛趁机涨了一波价。
为什么说是“误伤”?虽然RTX4090和H100都是GPU,但两者的设计思路截然不同。
比如,RTX4090的频率强于H100,因为更高的频率能够提供更强的图形渲染能力。而H100的强项则是理论算力、显存大小和显存带宽,这是因为AI推理和训练都非常考验数据的吞吐效率,这也是为什么H100需要昂贵的HBM3内存。
至于玩游戏,H100甚至都不支持主流游戏的图形接口。这也符合英伟达官方的“消费类”和“计算类”归类。
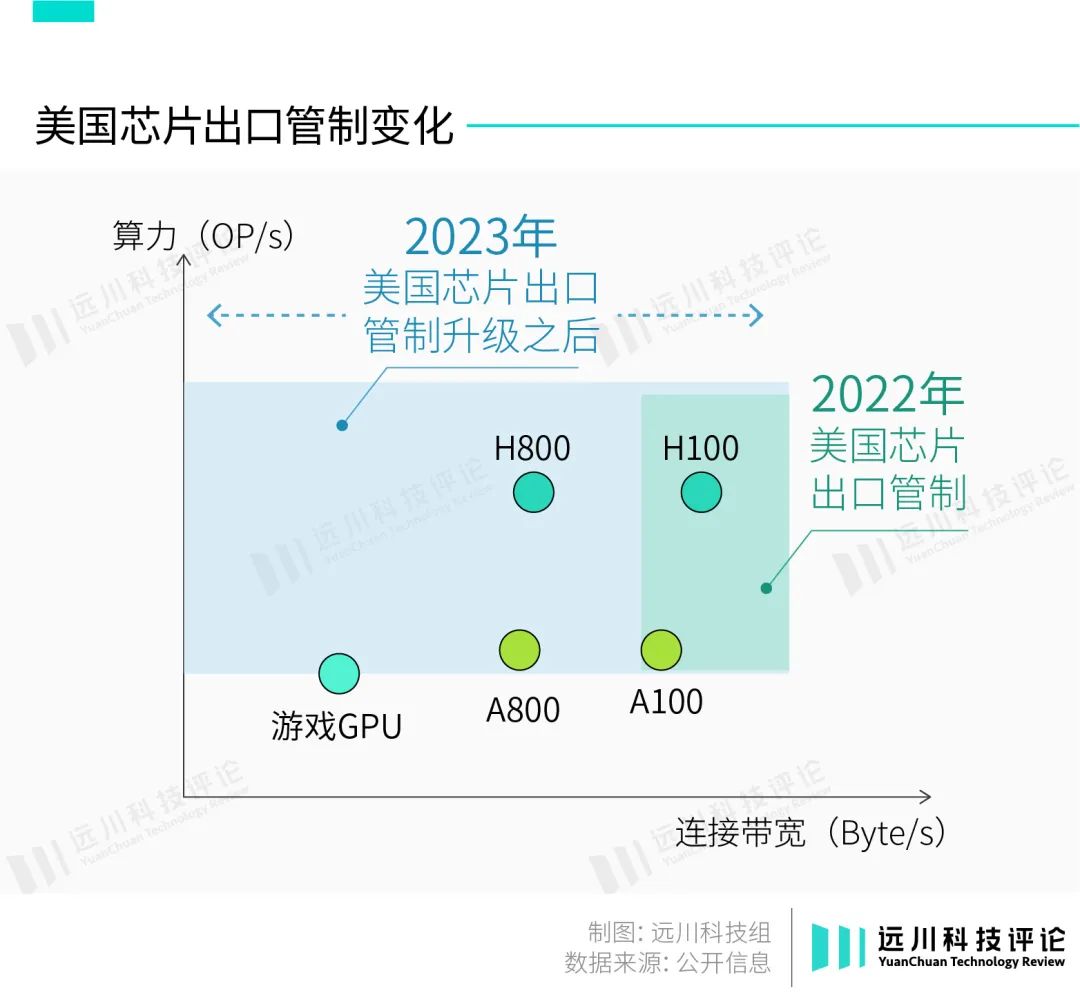
在一些讨论中,RTX 4090由于更低的价格、不差的算力、更低的功耗,一度被认为同样可以用于高性能计算。
客观地说——铁了心也能用。但一般而言,RTX 4090由于显存和带宽的限制,最多只能用作推理芯片。
AI芯片根据部署位置区分,大致上可分为云端芯片和终端芯片。云端芯片用于训练模型,俗称训练芯片;终端芯片用于终端设备,根据训练好的模型对实时数据执行推理任务,俗称推理芯片。
职责不同,导致对训练芯片和推理芯片的性能要求也有很大差异:
训练芯片需要通过海量数据训练可靠的模型,因此对数据传输速率、算力等指标有相当极端的要求。这也是为什么H100不惜用上昂贵的HBM内存和CoWoS封装,目的都是为了数据吞吐效率。
“特供版”的H800和A100,阉割的也是内存带宽,算力其实没有变化。
推理芯片一般处理实时任务,对于低延迟的要求更高,而且由于部署在终端,还要考虑功耗、大小、成本等问题。因此,用RTX4090这类消费级显卡强行训练,过低的带宽会带来“内存墙”的问题。
无论是谷歌的TPU、还是特斯拉的FSD芯片,大部分应用场景都是推理。大部分国产AI芯片,也都是走推理芯片的路子。
而在训练芯片这个场景下,英伟达的确是目前最好的选择。
从绝对的算力来讲,H100并不是巅峰。但在AI训练这件事上,一口气买几百块显卡的科技公司更在意的是另一个指标:单位成本的算力。
这也是为什么大家宁愿加价抢H100,也不愿意买“青春版H100”A100:按照H100 SXM版本、A100 80GB SXM版本8月的销售价格(24000美元、15000美元)计算,每单位算力的成本分别为12.13美元、24.04美元,H100 SXM优势明显。
另外,数据中心搭建完成后,还需要考虑电力、运维、故障、后期支持等多方面成本。种种因素叠加,大家还是老老实实地拿起了号码牌,加入了漫长的H100等待序列中。
比如特斯拉,前脚宣布给自研的Dojo超级计算机投10亿美元,后脚就透露要购买10000张H100用于驱动AI负载。
简而言之,在推理场景下,英伟达尚有替代方案;但在训练芯片里,英伟达是事实上的唯一方案。
原因在于,英伟达真正的护城河,是软件。
隐形的护城河
今年10月10日,AMD宣布打算收购一家名为Nod.ai的AI开源软件初创公司,以补足其软件短板。
虽然贵为GPU行业的世界第二,但长期以来AMD的市场份额只能和英伟达二八开,在以AI为代表的高性能计算市场,存在感就几乎为0。
事实上,AMD的AI芯片理论参数并不差,与H100对标的MI250X,虽然在FP32/FP64精度下的算力略逊于H100,但考虑到10000美元的售价,MI250X的“单位成本算力”其实更高,理论上可以成为比H100更好的选择。
但实际上,不管是大公司还是创业公司,大家还是更喜欢H100。原因就在软件,也就是大名鼎鼎的CUDA。
众所周知,GPU最初的目的是为游戏和视频进行图像渲染。黄仁勋是几乎所有奥斯卡“最佳视觉效果”提名影片背后的男人。2007年,英伟达还曾获得一个分量十足的奖项:艾美奖,以表彰其对娱乐行业作出的重大贡献。
首先发现GPU被大材小用的是华尔街精英,在渲染图像时所用到的并行计算能力,正符合金融场景里高频交易的需求。
不过,在用GPU跑交易之前,得先编写大量的底层语言代码,这显然劝退了一大批交易员。
为了降低GPU的编程门槛,David Kirk说服黄仁勋在2006年推出CUDA,CUDA的全称是Compute Unified Device Architecture,即计算统一设备架构,其作用也直白地写在名字里了:为GPU编程提供统一架构,使之满足不同应用场景下的算力需求。
伴随CUDA推出的是一本编程指南,里面详述了实现性能的具体方法,并且随着产品的升级迭代不断更新,至今已更新到12.3版。

最新版CUDA编程指南
这样的说明书在今天看来是基础必备,在当时与竞争对手的差距也不过两年,但先发者的一步领先却足以定义行业。
CUDA推出后,英伟达迅速打开了新业务的大门,在航空航天、天文学、气象学领域里都有GPU的身影。
2009年,苹果的开发团队推出OpenCL,支持者包括AMD和英特尔,希望能凭借着通用性在CUDA身上分一杯羹。但作为追赶者,OpenCL平台上的开发者天然地更少,很容易陷入恶性循环。
而CUDA则在“使用人数越多,CUDA平台就越好用,新开发者就越倾向于选择CUDA”的良性循环中,加固了生态优势。
深度学习爆发后,许多学习框架要么是在CUDA发布之后才会支持OpenCL,要么压根不支持OpenCL,使得OpenCL始终无法触及更高附加值的业务[5]。
2016年,AMD自家软件ROCm姗姗来迟,在投入不如英伟达的情况下,服务更新上滞后于CUDA,因此也难与CUDA抗衡。
芯片的架构和制程可以靠一两代产品迅速拉近差距,但一个成熟的生态系统却很难被破坏。CUDA生态遍布各行各业,从企业蔓延到教育系统。吴恩达曾评价:
CUDA出现之前,全球能用GPU编程的可能不超过100人。而目前全球的CUDA开发者已经达到几百万。
从某种程度上来说,CUDA已成为行业的事实标准。它的另一个特点是:只能和英伟达的硬件适配。
因此,任何开发者想要脱离CUDA生态,都不得不考虑标新立异的成本和风险。
不过对英伟达来说,繁荣的CUDA生态既是一座令竞争对手望而生畏的高山,却也是自己的软肋所在。
英伟达在担心什么?
黄仁勋之所以如此着急,道理也简单:如果铁了心换掉英伟达,也不是不可以。
英伟达固然是人工智能得以走上时代舞台中央最大的功臣之一,但在当下,它却存在两个不容忽视的问题:
一是成本过高。以“地表最强GPU”H100为例,首发价为3.3万美金,如今二手市场价格更一度上涨至5万美金左右。
科技公司如果要搭建拥有一万块H100的数据中心,即便不考虑其他成本和后续开支,光GPU采购费就需要数亿美金——即便对《财富》世界500强排行榜上的科技公司来说,这也不是笔小钱,更遑论初创企业。
二是通用芯片难以实现差异化。堆叠算力不是简单往车里加汽油,需要考虑软件适配性、自身业务需求等一系列问题。更何况,如果只用英伟达的GPU,意味着只有当英伟达出新产品,自家产品才能跟着升级,彻底将战略主动权交给了黄总。
这就是英伟达面临的一个尴尬情景:自己的客户都是自己的对手。
早在2014年,谷歌已开始了自研芯片的计划,其最新成果就是TPUv5系列。对参数量小于200B的大模型来说,TPUv5在推理时更具性价比,相较于英伟达GPU有着肉眼可见的成本优势[4]。

谷歌的TPU
而在重要的中国市场,美国的出口管制实际上在给黄总帮倒忙。
如前文所述,英伟达的核心壁垒在CUDA组成的繁荣生态——它就像一个无数开发者组成的“圈子”,后来者想要进入AI产业,就得融入这个圈子。如果把一部分开发者拦在圈子外面,那么他们最有可能做什么呢:
组建一个自己的圈子。
事实上,英伟达非常清楚这一点,其法律顾问Tim Teter就曾这样警告华盛顿:你冒的风险是刺激了一个由竞争对手主导的生态系统的发展,这可能会对美国在半导体、先进技术和人工智能领域的领导地位产生非常负面的影响。
如果“被踢出圈子”的概率只有1%,那大家只会把它当作一个黑天鹅事件;但一旦这个概率上升到哪怕只有10%,就一定会有人行动起来。这也是为什么英伟达对美国的出口管制如此警觉——中国科技公司会铁下心来掀桌子,开始搭建自己的生态。
英伟达并非是唯一有着类似境遇的公司,英特尔与高通也一同参与到了施压美国政府的行动当中。它们的一部分竞争力同样来源于生态的构建,英伟达的境遇让这两家芯片巨头深感唇亡齿寒。
要知道,上一轮针对英伟达的出口管制发布后,英特尔专门把Gaudi 2芯片的发布会放在北京开,一口一个“帮助构建中国人工智能的未来”、“携手中国产业生态”,趁机挖黄总墙角的心思昭然若揭。
结果新版出口管制出炉,AMD的MI250X、MI300,英特尔的Gaudi 2、Gaudi 3和黄总一起上了名单。这也难怪有小道消息说,英特尔高层和美国高级官员交涉时[2],一度急得指着对方鼻子问“到底懂不懂半导体?”
尽管相比美国,国内的芯片产业整体的差距并不小,但长期的封锁,一定会加速中国芯片产业的发展。一旦这个过程开始,也许就不可逆了。
这就是英伟达害怕的、美国众多芯片公司所担心的事情,正如黄仁勋所说[1]:There is no other China,there is only one China。
参考资料
[1] Chip wars with China risk ‘enormous damage’ to US tech, says Nvidia chief,Financial Times
[2] How the Big Chip Makers Are Pushing Back on Biden’s China Agenda,The NewYork Times
[3] Nvidia Makes Nearly 1,000% Profit on H100 GPUs: Report,Toms Hardware
[4] TPUv5e: The New Benchmark in Cost-Efficient Inference and Training for <200B Parameter Models,Semi Analysis
[5] 疯狂的H100,远川研究所
